Overview¶
任务¶
生成模型的核心任务就是建立概率分布,有了对概率分布的建模之后可以完成很多任务,这是回归模型所做不到的.
通常,我们建模的是变量之间的联合概率分布\(p(x y)\),从这个概率分布中我们可以导出某些概率或者生成一些我们需要采样的分布.
分类任务:
生成任务:
从x的分布中进行采样即可.
以及恢复图像破损,污染,被掩盖的区域:
异常检测,需要判定样本的生成概率小于某个值:
建模所需参数¶
考虑一个简单的伯努利分布,变量只有两个值0,1,如果用全参数建模,对于n个随机变量,需要\(2^n\)个参数才能精确描述.
如果考虑使用chain rule对概率分布进行展开:
那么则需要\(1+2+2^2+...+2^{n-1}=2^n-1\)个参数,只减少了一个参数,建模依旧不可行.
如果说考虑序列遵循马尔科夫过程,后者只取决于前者,那么chain rule可以简化为:
这样只需要1+2*(n-1)=2n-1个参数,然而,这种建模方式无疑是很粗糙的,并且只适用于特定数据和特定关系.
更加科学的建模方式是贝叶斯网络,即我们假设任何一个变量\(x_i\)仅仅由其父变量\(x_{Ai}\)决定,父变量有可能是一个或者几个随机变量,那么联合概率分布就可以写成:
这样,变量之间的关系就变成了一个图,这个图被称作贝叶斯网络,值得注意的是,这个图是无环的,否则就会出现逻辑上的矛盾,一个变量最终只依赖于他自己.
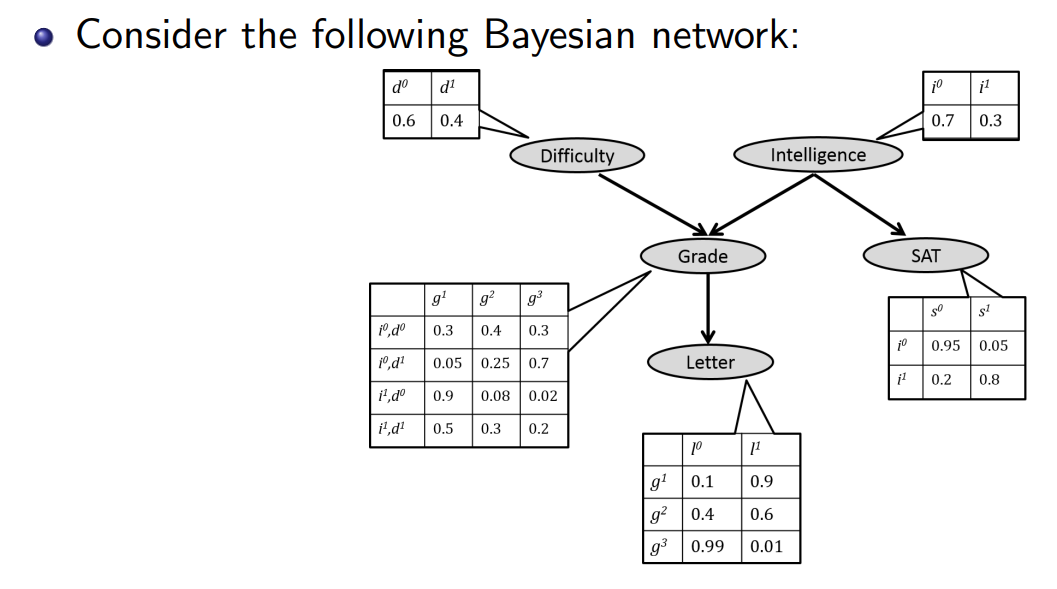
这种基于有向无环图的建模方式在结构确定上面临挑战。传统上,网络拓扑结构的构建强烈依赖于领域专家的先验知识.
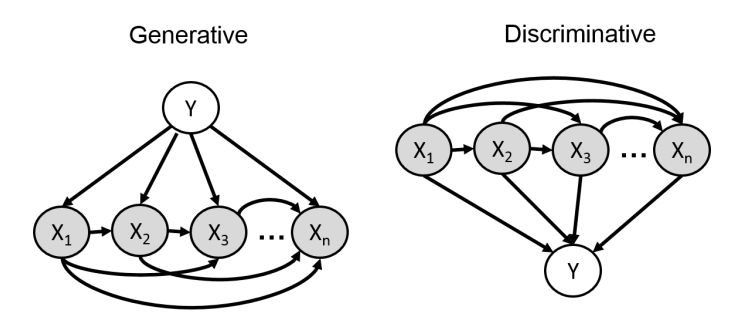
朴素贝叶斯分类器¶
朴素贝叶斯分类器就是一种简单的贝叶斯网络,他认为变量y依赖于x并且x之间互不相关: $$ p(x_1,x_2, \ldots ,x_n,y)=p(y)\prod_{i=1}^n p(x_i|y) $$
这些概率值都可以通过统计得到.
根据贝叶斯公式,就可以得到对样本的分类概率: