VAEs
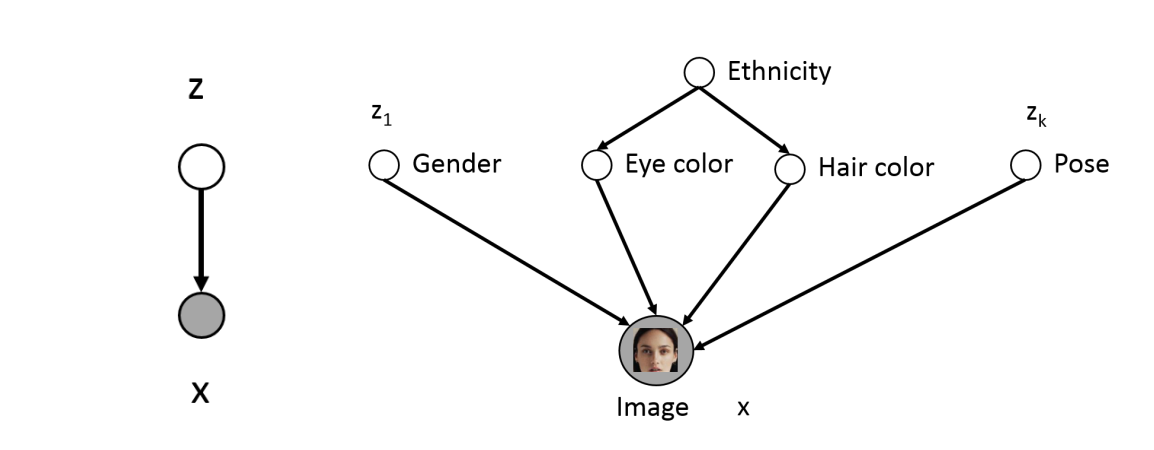
VAE的思想来源于这样一个事实,随机变量x往往由一些父变量决定,一旦能写出父变量的分布,建模\(p(x|z)\)往往要比直接建模\(p(x)\)要简单的多.
一个简单的例子,z遵循标准正态分布,条件分布x是许多正态分布的叠加:
\[ z \sim \mathcal{N}(0,1) , p(x|z) = \mathcal{N}(\mu_{\theta}(z),\sigma_\theta(z)) \]
z也可以是简单的离散概率分布,例如聚类任务中,z可能代表具有几个类别:
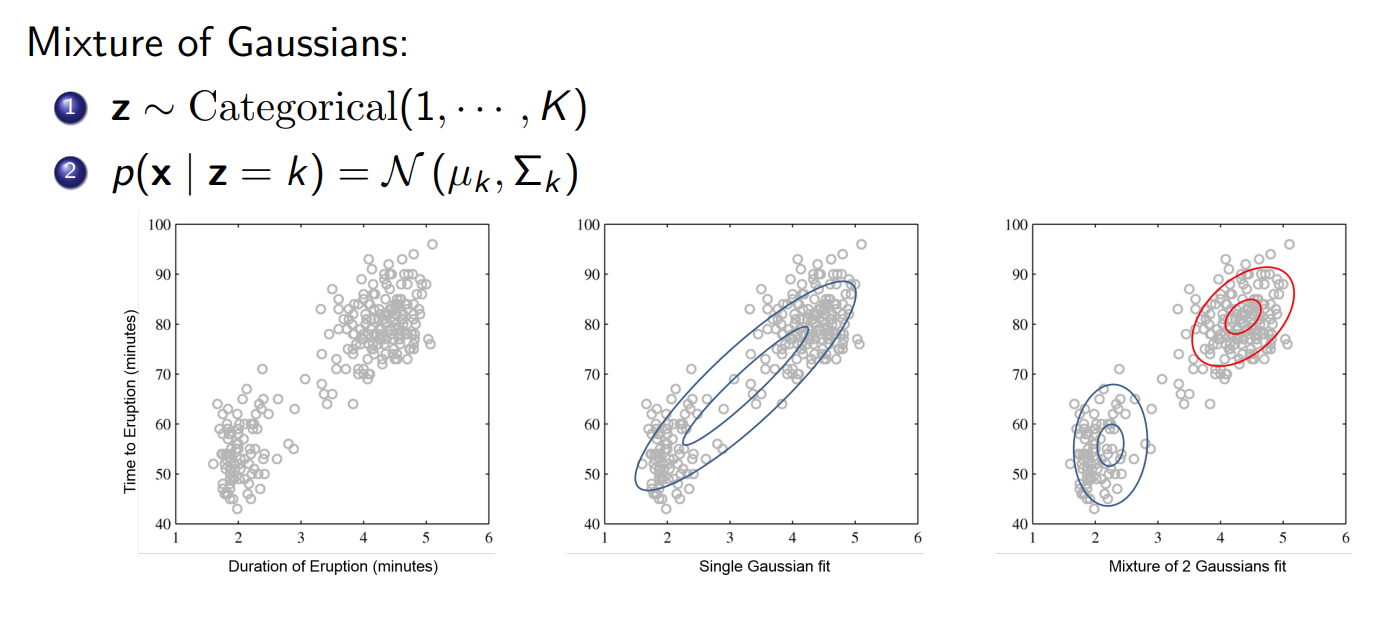
VAE的目标和其余生成模型的目标一致,都为最大似然:
\[ \sum_{x \in \mathcal{D}} \log p(x ; \theta) = \sum_{x\in D}\log \int p(x,z;\theta) dz \]
中间出现了一个积分,这个积分不好求解, 我们可以通过设置积分格点的方式将积分转化为离散求和,一种方式是均匀撒格点:
\[ \int p(x,z;\theta) dz = |Z|\sum_{z\in Z}\frac{1}{|Z|} p_{\theta}(x,z) = |Z|E_{z\sim \mathrm{Unifom}(Z)}p_{\theta}(x,z) \]
无论从积分格点还是从蒙特卡洛采样的角度,这个均匀采样都是相当低效的操作.
于是,通过引入一个新的分布,积分的形式可以发生改变:
\[ \int p(x,z;\theta) dz =\int q(z)\frac{p(x,z;\theta)}{q(z)} dz = E_{z\sim q(z)}\left[\frac{p(x,z;\theta)}{q(z)}\right] \approx \frac{1}{|Q|}\sum_{z\in Q} \frac{p_{\theta}(x,z)}{q(z)} \]
通过在分布\(q(z)\)中进行采样,可以合理的对这个期望产生估计,选择合适的q(z)相当于引入了合适的积分格点.
最好的q(z)一定要满足要求,即使用尽可能少的积分格点(采样格点)就可以达成高精度的积分值,注意到:
\[ p(x,z) = p(z|x)p(x) \]
故只需要令\(q(z) = p(z|x)\),也就是所谓的后验分布,那么等式就严格成立,并且只需要一个采样点.
最后,回到损失函数中,
\[ \begin{aligned} \sum_{x \in \mathcal{D}} \log p(x ; \theta) &= \sum_{x \in \mathcal{D}} \log E_{z\sim q(z)}\left[\frac{p(x,z;\theta)}{q(z)}\right]\\ &\ge E_{z\sim q(z)}\left[\sum_{x \in \mathcal{D}} \log\frac{p(x,z;\theta)}{q(z)}\right]\\ &= \sum_z q(z)\log p(x,z;\theta) - \sum_z q(z)\log q(z) \end{aligned} \]
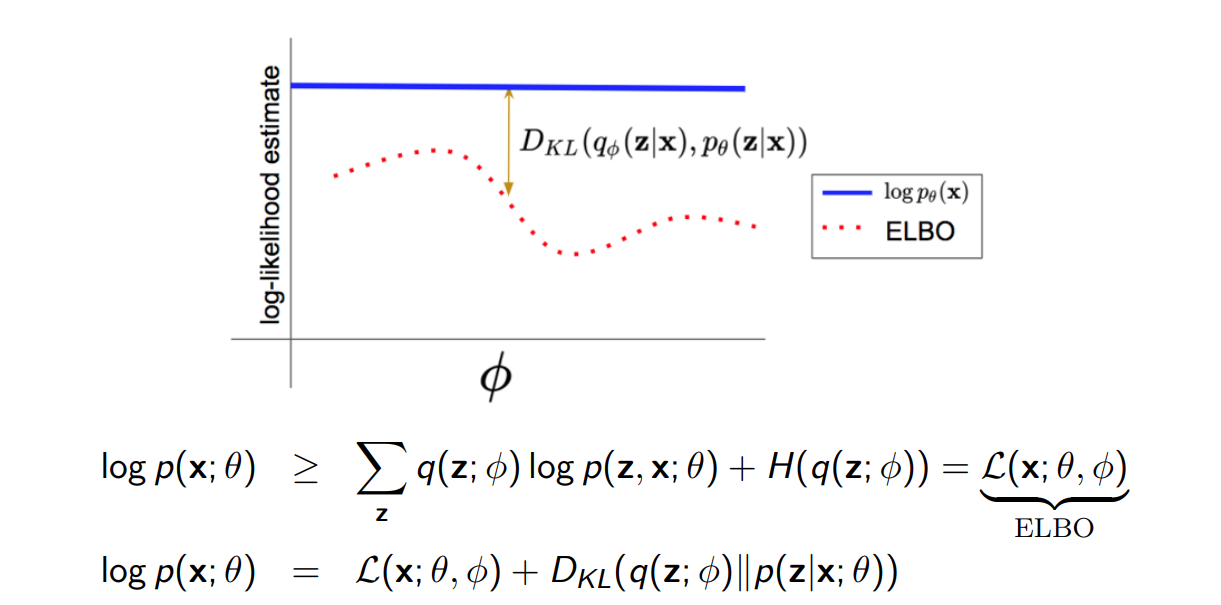
这个下界被称作 Evidence lower bound,简称**ELBO**.
注意,这里Jensen不等式取等的条件是q(z)刚好等于后验分布p(z|x),这个结论从KL散度中可以导出:
\[ D(q(z)||p(z|x;\theta)) = \sum_z q(z) \log \frac{q(z)}{p(z|x;\theta)}= \sum_z q(z)\log q(z) - \sum_z q(z)\log p(z|x;\theta) =H(q) + \log p(x;\theta) - \sum_z q(z)\log p(x,z;\theta)\ge 0 \]
由此可见,使得q(z)等于后验分布不仅可以从积分的角度很好的估计似然函数,而且还可以从不等式角度使得下界尽可能的接近上界.
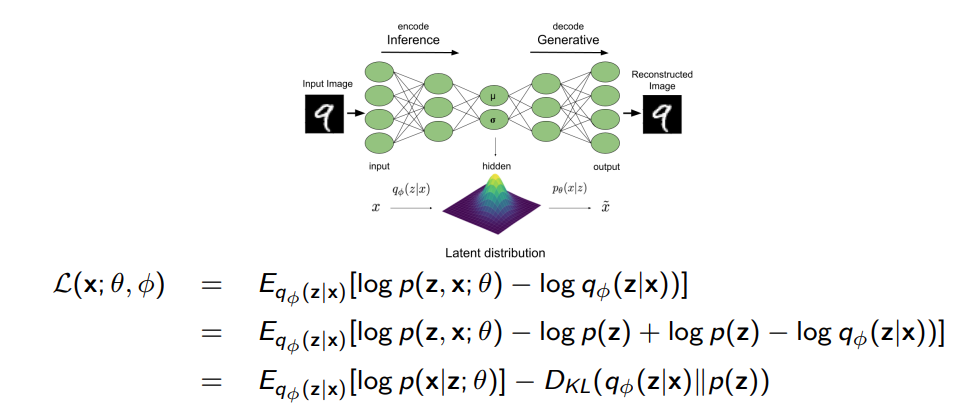
而ELBO的积分可以通过蒙特卡洛采样估计进行计算,q(z) = p(z|x)不能直接得到,也要使用一个神经网络进行映射,例如,我们假设后验分布式一是Gaussian分布,其通过编码器从x映射到Gaussian分布的均值和方差\(p(z|x)\approx q(z;\phi(x))\),这就是为什么VAE需要编码器.
当先验分布和后验分布是特殊形式的时候,例如gaussian分布的时候,ELBO的几项积分可以合并成KL散度并且解析计算,而只有部分才只需要使用采样估计,这也是为什么我们不直接估计原始的那个积分,而是要费尽心思弄出一个ELBO出来:
\[ \begin{aligned} \mathcal{L}(x;\theta,\phi) &= \sum_z q(z;\phi)(\log p(x|z;\theta)p(z)) - \sum_z q(z;\phi)\log q(z;\phi) \\ &=\sum_z q(z;\phi)\log p(x|z;\theta)+ \left[\sum_z q(z;\phi)\log p(z) + H(q(z;\phi))\right] \\ &=E_{z\sim q(z;\phi)}\left[\log p(x|z;\theta)\right] - D_{KL}(q(z;\phi)||p(z)) \end{aligned} \]
只有第一项需要采样来估计积分值,这一项被称作重建损失.p(z)通常采用标准正态分布\(p(z)=\mathcal{N}(0,I)\),q(z)是从encoder映射来的正态分布,\(q(z)=\mathcal{N}(\mu_{\phi}(x),\operatorname{diag}(\sigma^2_\phi(x)))\),其KL散度的计算结果为:
\[ D_{KL}(q(z;\phi)||p(z)) = \frac{1}{2}\sum_j (\mu_j^2 +\sigma_j^2 - \log \sigma_j^2 -1) \]
VAE更像是一个规整的信息压缩生成器,Alice使用编码器压缩对应的信息到隐空间中, 而Bob使用隐空间的分布去重构可能的真实分布,KL散度限定了Alice发出的信息不能离先验分布太远,这样之后我们就可以从已知分布去直接采样,而重构项又确保了有足够的信息去还原图片.