Normalizing Flows¶
Invertible transformation¶
Flow Model是另一类模型,类比VAE从隐空间生成样本一样, Flow Model也是从z生成x,不同的是, VAE需要遍历所有的z,判断这些z是否和x有关,而flow model则认为一个z就唯一对应一个x, z遵循一些简单分布, 我们通过可逆变换的方式将简单分布慢慢变化到复杂分布上.如果变换是可逆的,不仅x和z是一一对应的,概率分布的转换上也有很好的性质,设\(x=f(z)\),则会有:
使用累积分布函数的定义即可证明.
将结论推广到多维前,先看线性变换的一个简单例子:
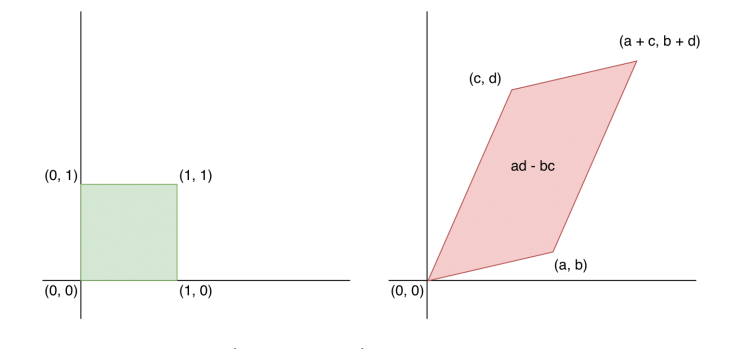
对一个二维的均匀分布的随机变量使用矩阵A进行线性变换\(X=AZ\),面积变成了\(|\text{det}A|\),而概率分布的积分值要为1,所以变量变换到Z之后要除掉相应的面积:
现在,将线性变换改为任意可逆变换,矩阵的行列式就会改为雅可比矩阵的行列式.
可以变换可以多步叠加:
每个变换的Jacobian矩阵的行列式会相乘:
通过多个简单变换可以将简单的分布映射到复杂的分布,简单可逆变换中存在神经网络可学习的参数,由于映射是可逆的,z和x必须始终保持相同维度,否则压缩可能会带来一对多的风险.
训练一般使用对数似然:
神经网络需要进行特殊的设计,他必须满足两个条件1.将参数放在可逆变换中. 2.Jacobian行列式要易于计算.
NICE¶
NICE是一个简单的flow model, 对任意一层的可逆变换, 考虑将x和z分成两个部分:
训练时需要评估似然,所以要从x->z,生成时从z->x:
根据\(z_a=x_a\),可以轻松得到反向变换:
NICE的Jacbian矩阵是一个下三角矩阵,计算行列式只和对角元有关:
于是,\(|\det J|=1\),也就是每一步可逆变换不改变局域体积.所以NICE为了增强表达能力,在最后的Rescaling layer对每个维度进行了缩放:
这一步的Jacbian是一个对角阵,$|\det J| = \prod_{n=1}^{N}s_n $.
Real-NVP¶
和NICE类似,但是在每一层的可逆变换中都增加了逐通道缩放,使得每一次变换都会使局域体积改变:
正向,z->x:
反向,x->z:
类似的,也可以得到Jacbian,也是一个特殊的下三角矩阵:

通过在隐空间中使用特殊的插值方法,可以生成丰富多彩的图像.
Autoregressive flow¶
连续的Autoregressive model可以视作一个flow model, 简称Autoregressive flow, 考虑这样一件事情,每次的条件概率都是Gaussian分布,Gaussian分布的均值和方差都由之前的x决定:
那么,从z到x就是一个很清晰的可逆变换过程:
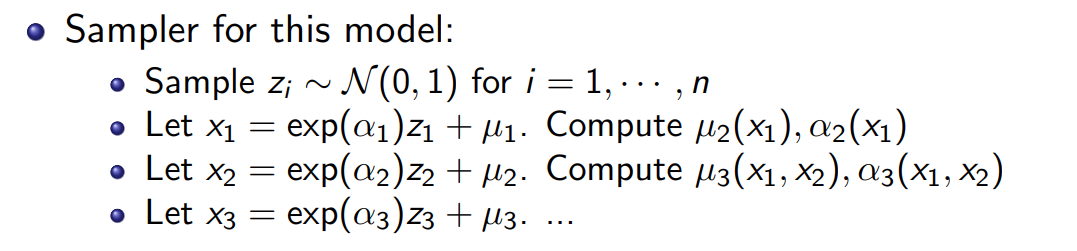
在图上表示就是这样的:
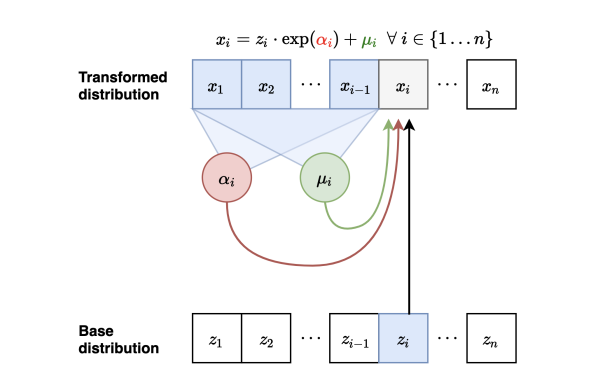
这种flow被称作Masked Autoregressive Flow(MAF).在训练的时候和Transformer一样,因为有x,可以直接并行评估所有的\(\mu\)和\(\sigma\),从而并行计算所有z,所以训练的时候非常快,可以很方便的从x到z,评估似然,但是生成的时候x要逐个生成,因此生成就变慢了.
另一类模型是通过z计算均值和方差然后变换成x,这类模型被称作Inverse Autoregressive Flow (IAF)

可以看到,由于均值和方差只依赖z,z通过一次采样生成,所以从z->x可以高效并行的完成,但是同样,反过来,从x计算z,评估似然的时候,需要一个个生成z,进而一个个生成均值和方差,因此这类模型在训练上非常慢.
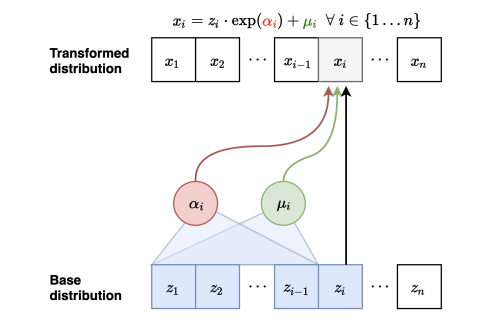
Parallel Wavenet¶
Parallel Wavenet是集合了上述两个模型优点的模型,他通过teacher-student方法使得IAF模型可以快速被训练,第一步,先训练teacher模型(MAF):
然后,从student模型中采样,同时用teacher模型评估似然,然后拉进student和teacher模型的KL-divergence:
由于x是student模型从z中采样的,所以可以直接评估概率,通过这样的方式,student模型生成的分布最终会接近teacher模型,但是推理速度要快得多.
Gaussianization Flows¶
Gaussianization Flows是一种Gaussian化的flow model,我们的最终目标是降低\(p_{\theta}(x)\)和实际分布\(p(\tilde{x})\)之间的KL散度,假设存在一个可逆分布,可以直接把x变换成z,z是标准Gaussian分布,对两个分布同时应用这个可逆变换,KL散度的数值不变,含义变为:\(D_{KL}(p_{f^{-1}_{\theta}(\tilde{X})}||p_Z)\),所以,也就是找到一个可逆变换将实际数据Gaussian化.
首先从一维的情况开始考虑:
Inverse CDF trick:对于实际数据的随机变量\(\tilde{X}\),其满足\(\tilde{X}=F_{data}^{-1}(U)\),其中U是0-1的均匀分布的随机变量:
同理,如果令随机变量\(U=F_{data}(\tilde{X})\),那么U服从0-1的均匀分布.
于是,对这个随机分布应用Gaussian的反CDF分布,就可以把均匀分布变成Gaussian分布(和Inverse CDF trick同理):
注意到CDF和反CDF都是单调的,所以这个变换可逆.
现在回到高维分布,这会稍微复杂一点,首先对每一个维度都应用Gaussianization,但是不同变量之间会出现耦合现象,这导致联合概率分布不一定是Gaussian,所以要先进行旋转,将各个分量进行混合,从而识别出可能的独立的Gaussian分量,然后再逐维度Gaussianization,不断重复这个操作,就可以把联合概率分布变成标准Gaussian分布:
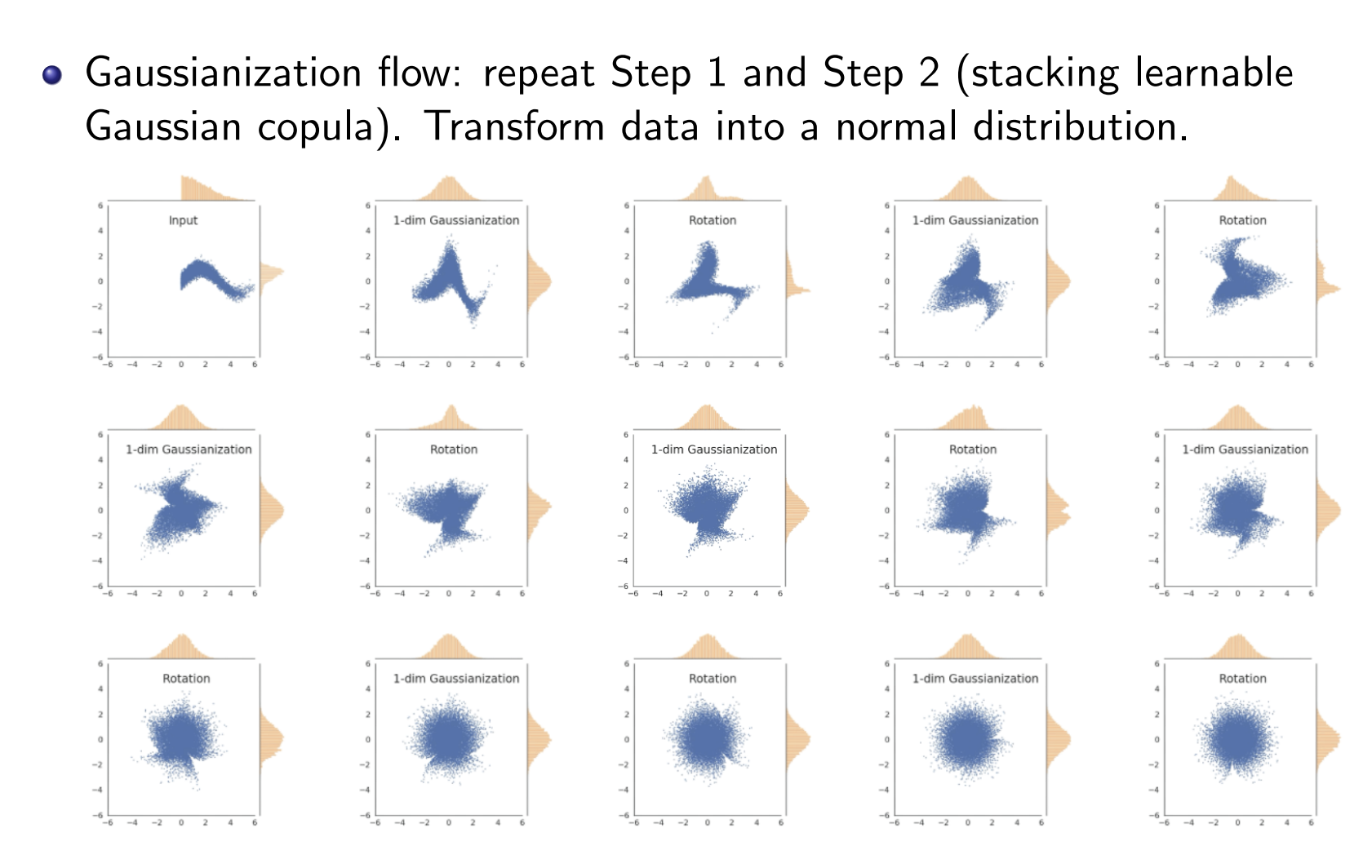
最终的变换总结为:
这里的\(\Phi_{\theta}\)是单独对每一维的随机变量先套CDF,再反Gaussian CDF,这里的CDF用神经网络模拟单调且范围为0-1之间的函数,旋转矩阵R也是可学习的,通过特殊的方式构造来确保矩阵的合法性.