Maximum Likelihood¶
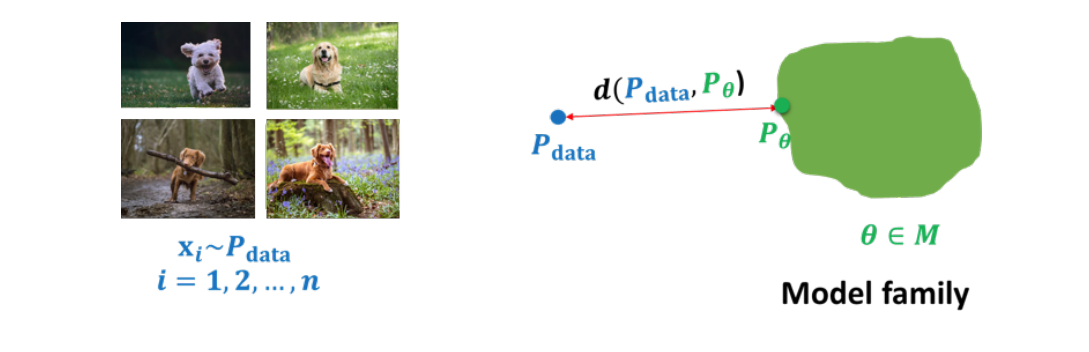
我们想要训练生成模型,其最终目的就是使得模型的分布和实际数据的分布达到一致,通过调整模型参数\(\theta\),可以得到一系列分布,我们需要定义一个距离来刻画这些分布和实际分布之间的差距,从而进行优化.
Kullback-Leibler divergence(KL divergence)即KL散度是度量两个分布之间距离的一个指标:
\[ D(p||q) = \int p(x)\log \frac{p(x)}{q(x)} dx = \sum_x p(x) \log \frac{p(x)}{q(x)} \]
为了方便起见,积分统一写成求和,涵盖连续变量和离散变量.
KL散度是非负的:
\[ D(p||q) = E_{x\sim p(x)}\left[-\log \frac{q(x)}{p(x)}\right]\ge -\log \left(E_{x\sim p(x)}\left[\frac{q(x)}{p(x)}\right]\right) = -\log \left(\sum_x p(x) \frac{q(x)}{p(x)}\right) = 0 \]
上面这步不等式用的是Jensen不等式,-log(x)是上凸函数.
在信息学角度,KL散度考虑的是模型对信息的压缩程度,在n进制下,对于事件x,其最优的编码长度为\(-\log_np(x)\),对于高频词汇给予较短的编码长度,对于低频词汇给予较长的编码长度.
所以,对于x,其在真实世界的平均编码长度为:
\[ H(p) = \sum_x -p(x)\log p(x) \]
这被称作分布p(x)的熵.
如果说,我们使用了估计的q(x)对x进行编码,那么实际的编码长度就被称作交叉熵:
\[ H(p,q) = \sum_x -p(x)\log q(x) \]
多出来的长度就是KL散度:
\[ H(p,q)-H(p) = \sum_x p(x) \log \frac{p(x)}{q(x)} \]
选定KL散度作为距离度量后,我们可以进一步化简:
\[ D(p||q)=E_{x\sim p(x)}\left[\log \frac{p(x)}{q(x)}\right] = E_{x\sim p(x)}\left[\log p(x)\right]-E_{x\sim p(x)}\left[\log q(x)\right] \]
第一项和优化无关,是一个常数,故我们选定第二项作为我们的损失函数:
\[ \mathcal L(x;\theta) = -E_{x\sim p(x)}\left[\log p_{\theta}(x)\right] \approx - \frac{1}{|\mathcal{D}|}\sum_{x\in \mathcal{D}} \log p_{\theta}(x) \]
使用样本估计总体的期望,最终只需要将所有样本的似然函数最大化即可,故称最大似然.