Autoregressive Models¶
自回归模型是对概率分布建模的一种新的方式,他使用一套共用的神经网络参数去描述条件概率,而不是使用查询表对概率进行建模:

如果使用贝叶斯网络进行建模则是如下图所示,这种不依赖任何假设的贝叶斯网络具有自回归性质
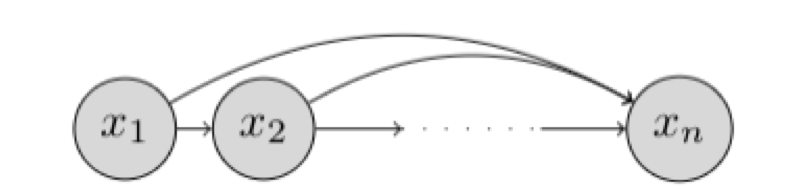
也就是说,对于联合概率密度的建模可以写成这样的形式:
根据先前的自回归假设,条件概率可以写成前几个随机变量的函数,这个函数可以是一个神经网络或者一个简单的非线性单元:
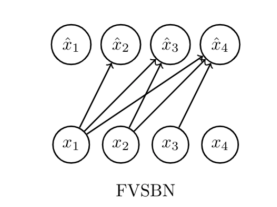
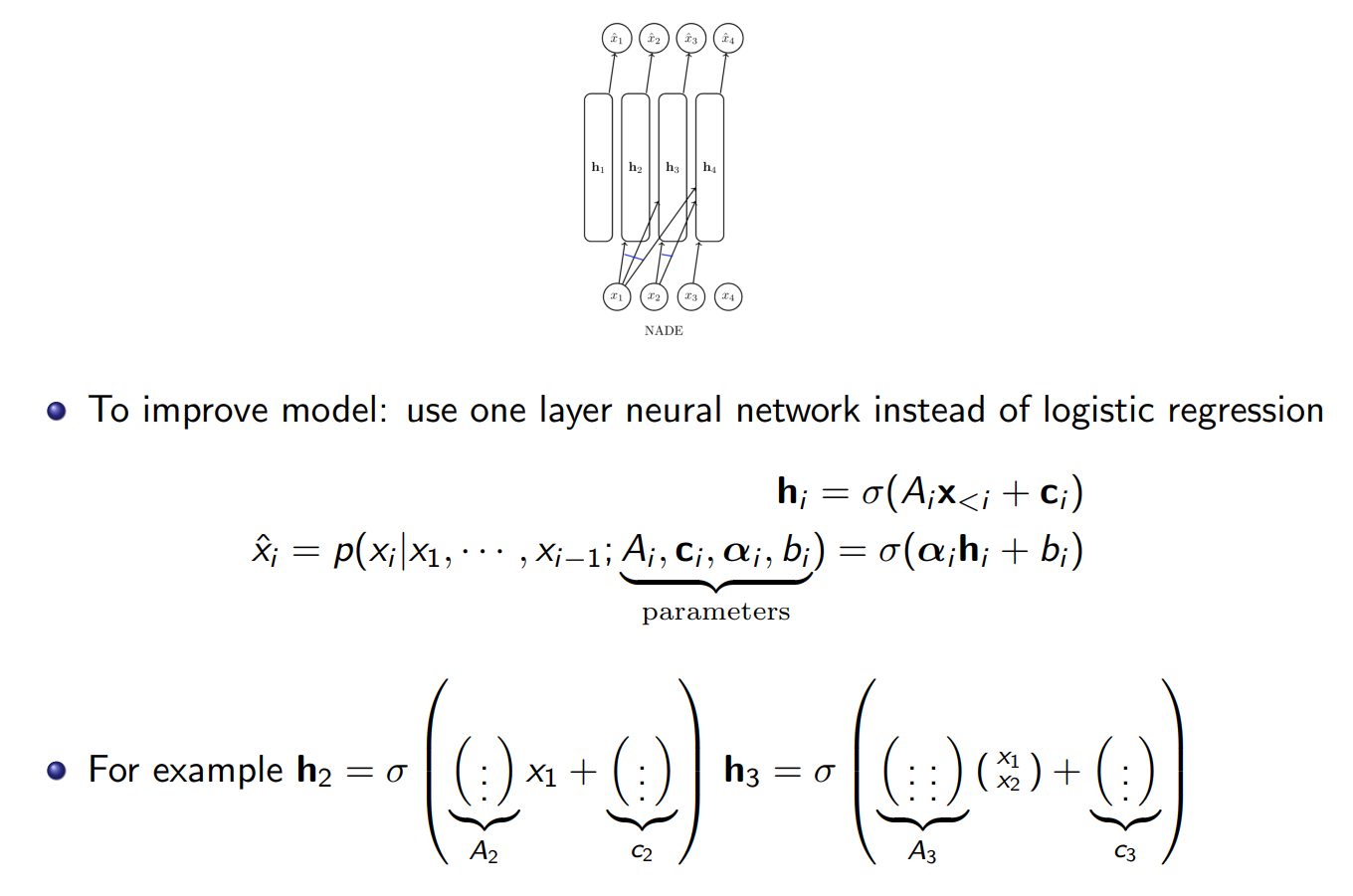
这种简单的结构被称作Fully Visible Sigmoid Belief Network(FVSBN).更一般的,将简单的单层线性层和激活函数改成神经网络,得到的模型如下所示,被称作Neural Autoregressive Density Estimation,这里是初始化一个大的矩阵,做自回归预测的时候,有几个x就激活几列,其实还有一种更加参数高效的方法,类似CNN,我们可以设置一个滑动卷积核,比如固定为i列,小于i的就按照原本的方案进行,大于i的,当前变量只和前i-1个变量相关,使用共享参数的卷积核(系数矩阵)来捕捉这种相关性,当然,这个方案有个缺陷,必须确保变量按照一定顺序排列,并且有相关性衰减.
对于连续随机变量,x_i有无限个取值,不能按照上面的方法进行建模了,可以使用K个高斯分布去近似拟合实际分布:
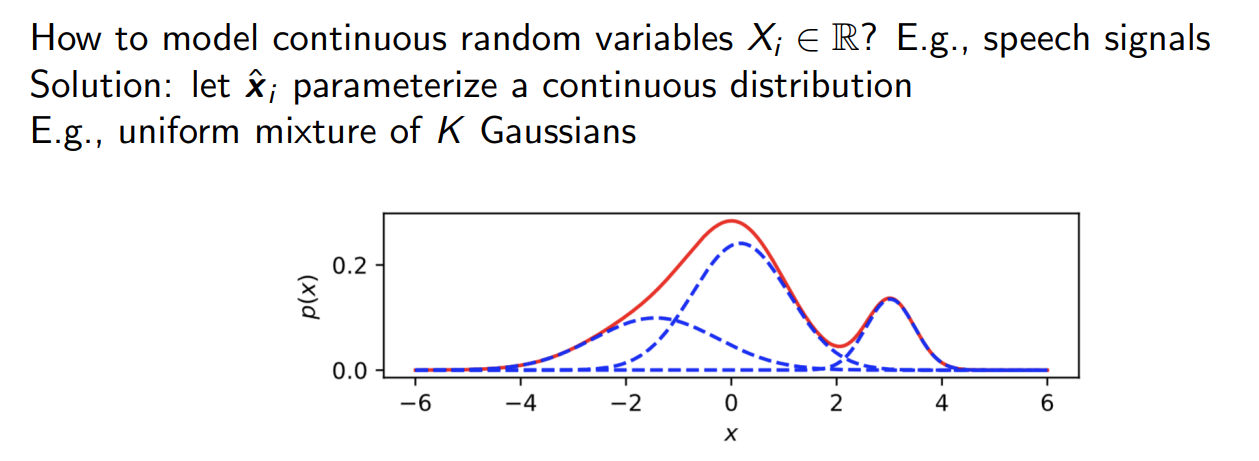
这样,随机变量就被2K个固定数值代表了,\(\mu,\sigma\),然后套用上述的自回归神经网络模型.
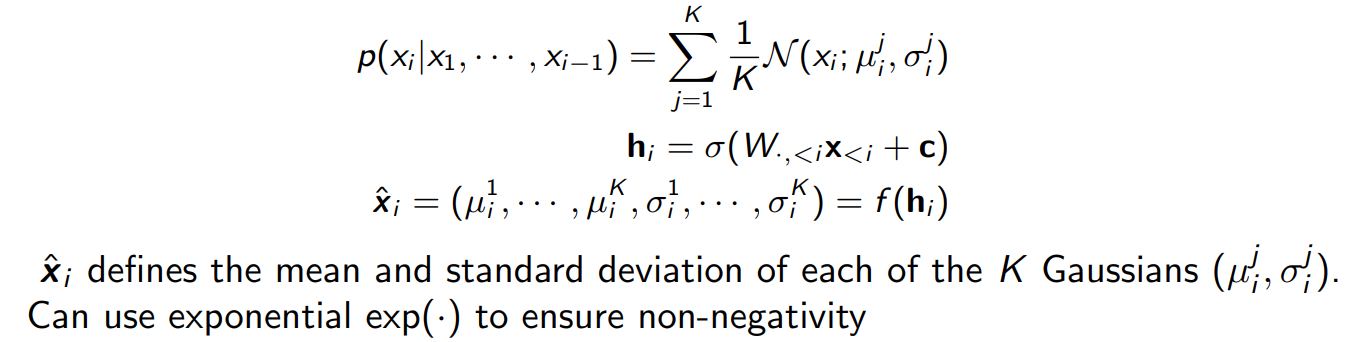
最典型的auto-regressive model就是RNN和transformer,后者由于并行效率的优势在自然语言处理占据绝对的主导地位:
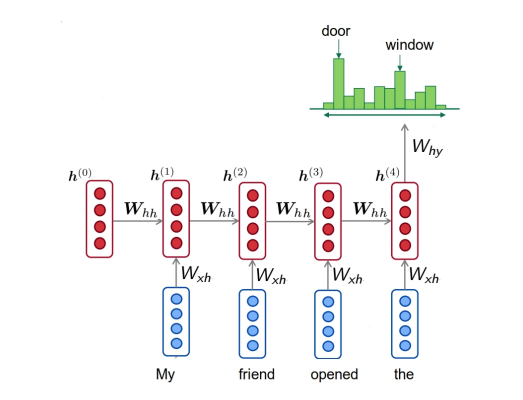 | 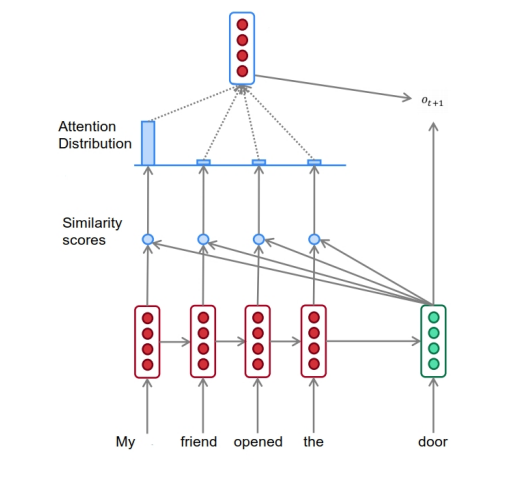 |
|---|---|
| RNNs | Transformer |
除了在文本领域,自回归模型还可以用于精细的图像生成,例如Pixel RNN, 逐个逐个像素点生成,可以生成非常精细的图案:


代价也很明显,由于是自回归架构,生图的速度非常慢,同时训练也很慢,为了解决训练的并行化问题,有人专门提出的pixelCNN, 本质上是根据四周的像素点去预测中心的像素点,同时中心,右边和下方的像素点会被mask掉.
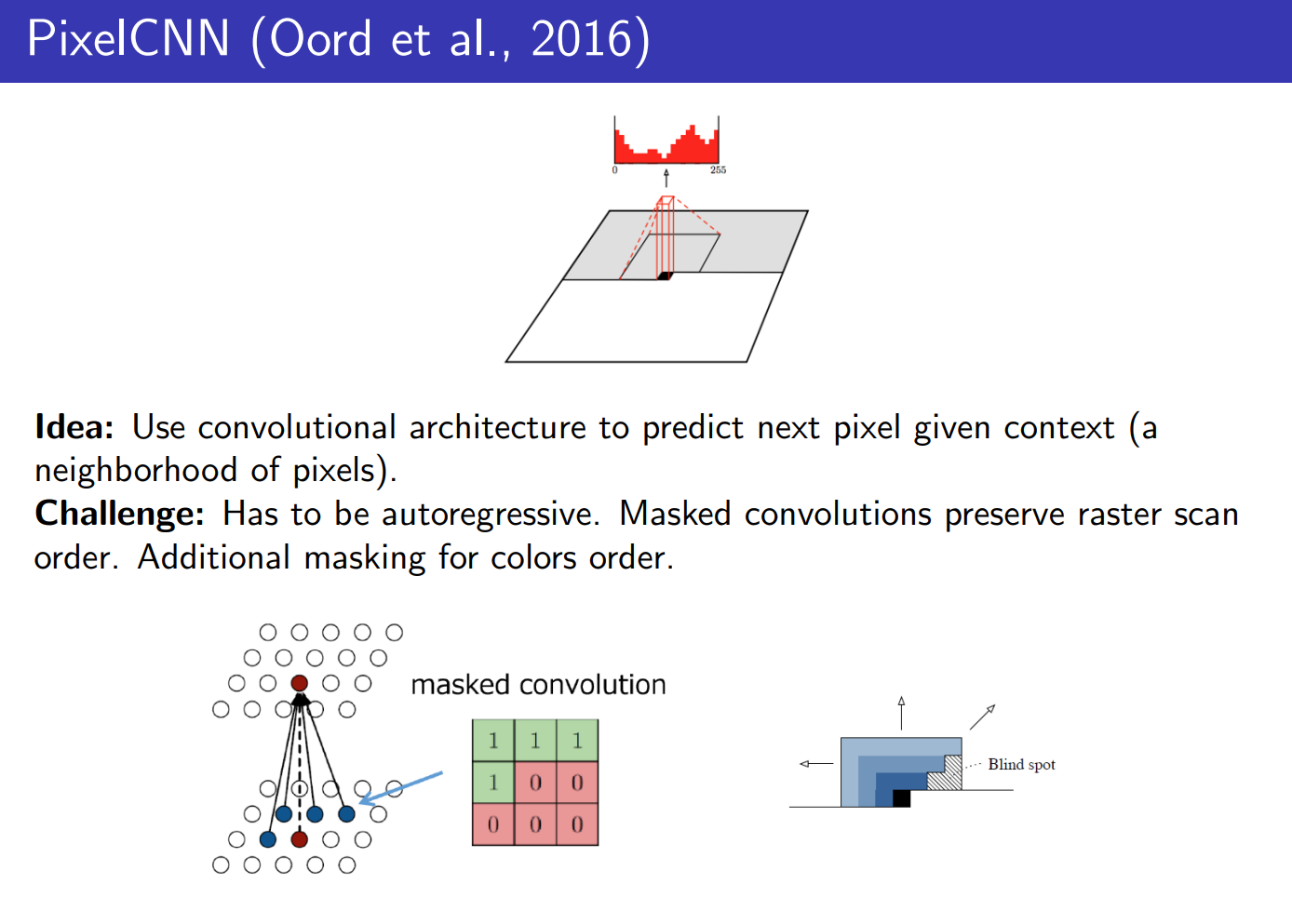
同样缺点也很明显,就像这张图里显示的,会出现Blind spot,由于要进行mask,而随着卷积层数的加深,感受野并不能覆盖所有的历史像素,出现了信息利用不完全的现象.
对于自回归模型非常好的一点就是,它可以给出当前随机变量的采样概率,这样就可以用来做异常值检测,当前很多针对图像识别模型开发了专门的攻击数据,一张图片,加了噪声之后,人脑判定他们是同一张照片,但是对于在干净数据上训练的机器学习模型,它对噪声非常敏感,会把他识别成别的东西:

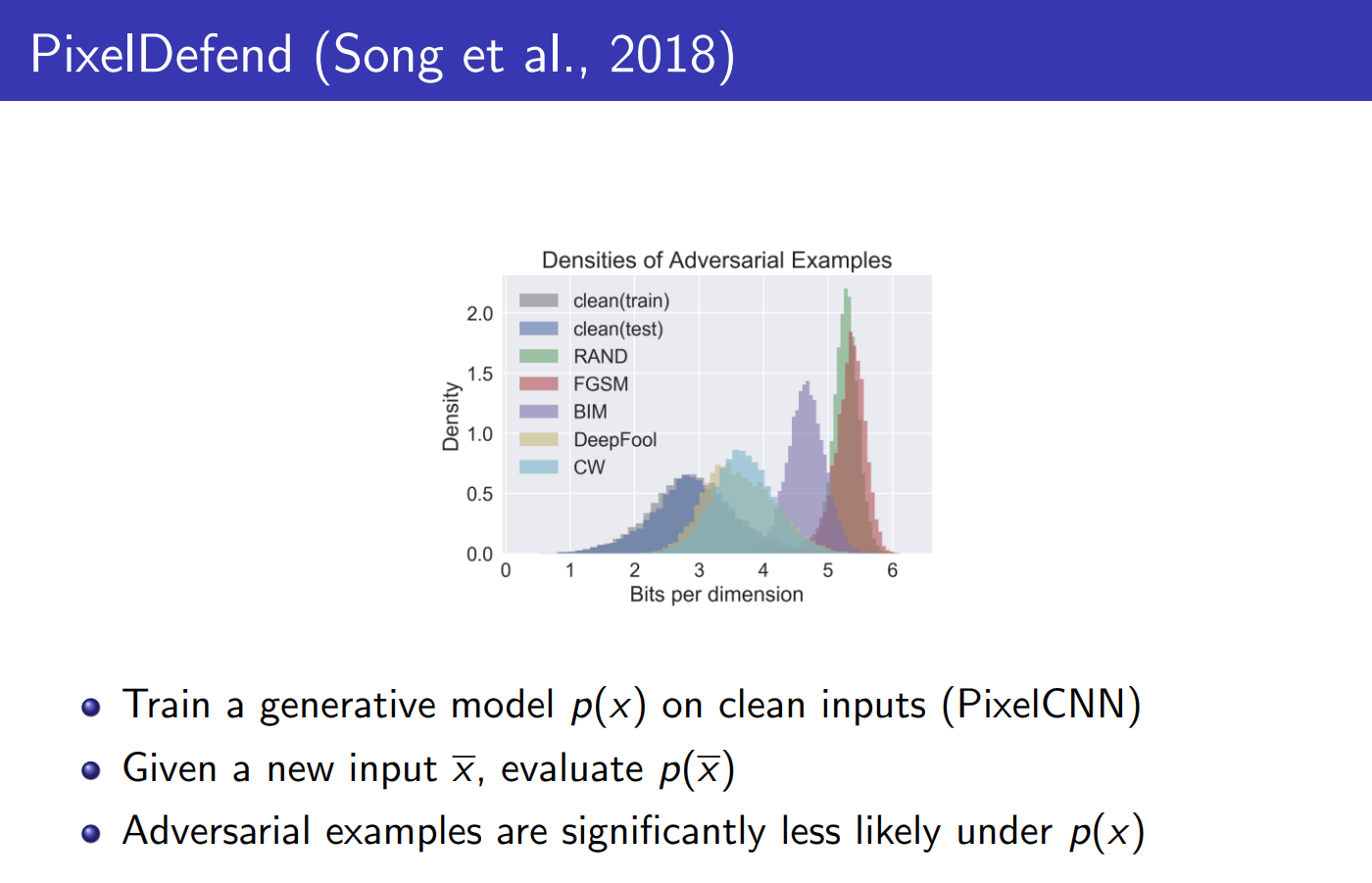
使用在干净数据集上训练的生成模型就可以给出当前图片的似然,从而判断他是不是攻击样本,这张PPT里面的横坐标是Bits per dimension,和似然的关系是:
D是像素的维度数量.因此,bpd越大,越不像是正常样本.